运行环境: python 3.6.0
关于如何判断一个字符串是否含有中文这个问题,那么一定得知道什么是编码,计算机不会直接告诉你什么是中文,什么不是中文的,计算机只认识二进制,一切的字符在计算机中都是以二进制的形式进行存储,计算机同时也只能运行二进制。
我们平时在计算机中所见到的所有字符都是以ascii码表的形式存储的,然后对应的 adcii 以相应的方式转存为二进制,但是在 ascii 码表中并存不下中文,因为中文实在是太多了,但是中国人聪明啊,两个8位组合起来来存储中文就够了么,然后就有了unicode码。
解题思路: 我们可以首先可以获取中文的unicode码范围,然后用正则表达式判断一个字符串内是否含有中文了
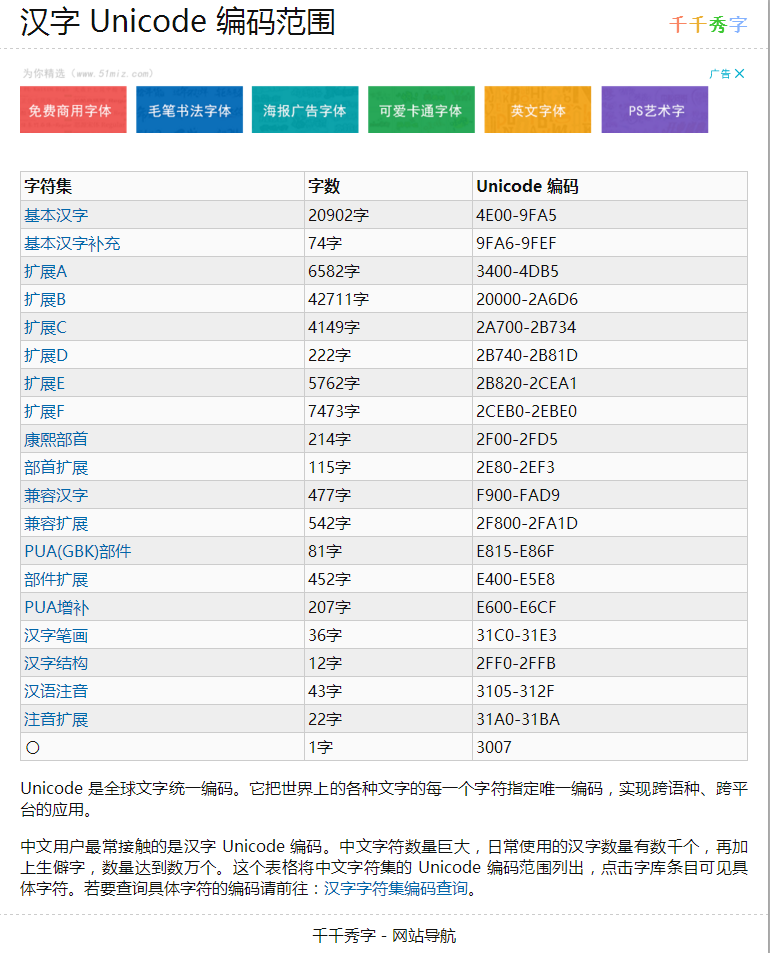
unicode 码表: https://www.qqxiuzi.cn/zh/hanzi-unicode-bianma.php
从 unicode 码表我们知道 unicode编码的范围是 4E00-9FA5
代码如下:
# -*- coding: utf-8 -*-
import re
zh_pattern = re.compile('[\u4e00-\u9fa5]+')
def chinese_detection(string_word):
"""
判断传入字符串,判断是否包含中文
:param string_word: 传入的要检测的是否含有中文的字符串
:return: True or False
"""
if re.search(pattern=zh_pattern, string=string_word):
return True
else:
return False
def main():
"""
主函数
:return: None
"""
while True:
string_word = input('please input a string: ')
if string_word == "0000":
print("########## EXIT ##########")
exit()
else:
result = chinese_detection(string_word=string_word)
print(string_word)
if result:
print('''this string has chinese''')
else:
print("""this string don't have chinese""")
print()
if __name__ == '__main__':
main()
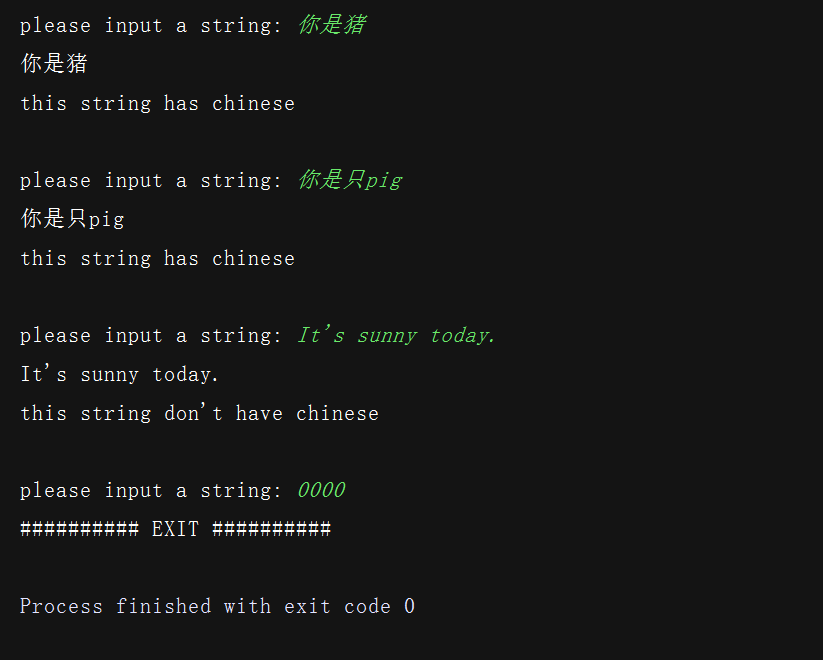
运行结果示例: