做爬虫最大的困扰就是对方的反爬措施,最好不要强攻,能绕过就绕过,毕竟上网需要科学
selenium 指纹被做了记号如何破?这个时候说明对方已经检测了你的行为特征,这是一个比较严肃的问题,尤其是在破解滑动验证码的时候
大厂的技术团队还是给了我们一个更难解决的问题,就是通过 js 给 webdriver 请求响应错误信息,所以我们要做的是把这些影响科学上网的 js 代码给废掉
这里的方法是通过 mitmproxy 蔽掉识别 webdriver 标识符的 js 文件。
1. mitmproxy 安装。
pip install mitmproxy
2. 启动 mitmproxy 并指定端口。(这一步只是运行方式,这里这一步可以不用运行)
windows:mitmdump -p 8001
Linux:mitmproxy -p 8001
3. 新建文件 httpproxy.py
# -*- encoding: utf-8 -*-
import re
INJECT_TEXT = 'Object.defineProperties(navigator,{webdriver:{get:() => false}});Object.defineProperty(navigator, "plugins", {get: () => new Array(Math.floor(Math.random() * 6) + 1),});Object.defineProperty(navigator, "languages", {get: function() {return ["en", "es"];}});'
def response(flow):
match = re.search(r'\.js$',flow.request.url)
if match:
# 屏蔽selenium检测
flow.response.text = INJECT_TEXT + flow.response.text
print('注入成功')
#flow.response.text = flow.response.text + INJECT_TEXT
4. 将 mitmproxy.py 挂载起来
mitmdump -s httpproxy.py -p 9090
5. selenium 连接端口并运行程序
# -*- encoding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--proxy-server=http://127.0.0.1:9090')
driver = webdriver.Chrome(options=options)
url = 'https://www.zhihu.com/'
driver.get(url)
web = driver.execute_script("return window.navigator.webdriver")
print (web)
driver.close()
# 输出
False

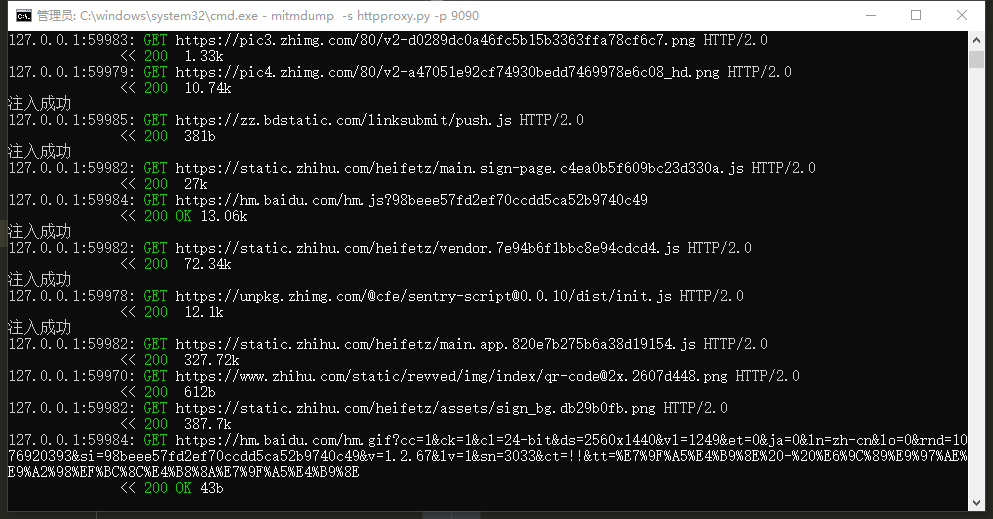
这些简单的 js 对于普通的问题不大,这个地方对 js 功底要求还是很严格的